
Attention Is All You Need
기존 RNN도 계속 발전하면서 Attention 매커니즘을 적용했지만, 모델 구조상 Long Term Dependency 문제를 해결할 수 없었음 (정보 유실 문제)
이런 근본적인 문제를 해결하고자 "Attention Is All You Need" 논문 제목처럼, RNN(혹은 CNN) 구조를 완전히 걷어내고 Attention 구조만을 활용해서 Transformer 모델을 구성함

최종적인 목표는 이미지처럼 Transformer를 거쳐서 언어 번역을 하는 것임
Components of Transformer
Scaled Dot-Product Attention

헷갈리던 내용들 위주로 정리
1. Thinking, Machines 각각 단어이다.
2. 각각의 단어에서 (동일한 출처에서) Query, Key, Vector가 도출된다.
3. Query, Key, Vector는 각각 내적 연산을 하는 $W_K$, $W_Q$, $W_V$에 의해서 구분된다.
예를 들어, Thinking이라는 한 단어를 $x_1$이라고 하면 Query, Key, Vector 각각은 다음과 같다.
Query: $x_1\cdot W_{q_1}$ = $q_1$
Key: $x_1\cdot W_{k_1}$ = $k_1$
Vector: $x_1\cdot W_{v_1}$ = $v_1$
이렇게 한 단어에 대해 Query, Key, Vector가 각각의 독립적인 $W$에 의해 결정되어 나온다.
각각의 역할을 알아보자.
Query: 어느 벡터를 선별적으로 가져올지 기준이 되는 벡터
Key: Query 벡터와 내적이 되는 벡터, 해당 Query 벡터에 대해 어떤 Key 벡터가 높은 유사도를 갖고 있는지를 결정
Value: 가중 평균의 재료가 되는 벡터
어차피 각각의 벡터의 $W$는 독립적이기 때문에, Gradient Descent를 기반한 Backpropagation으로 목적대로 수렴해 갈 것임

위 내용을 바탕으로 이미지를 이해해보자
1. 'I', 'go', 'home' 각각 단어를 가지고 각각 Q, K, V를 만듦
2. 'I'의 Query인 $q_1$에 대해 'I'의 Key인 $k_1$, 'go'의 Key인 $k_2$, 'home'의 Key인 $k_3$와 각각 내적하기
3. 각각 내적한 값에 대해 softmax 변환
4. 해당 softmax값과 각각 단어에 대한 Value로 내적한 값이 최종 Attention 값
5. 'go'와 'home' 의 Query인 $q_2$와 $q_3$에 대해서도 동일하게 진행
6. 아래에 최종적으로 나오는 식에서는 이 과정을 Matrix로 확장해서 모든 단어의 $q$ 즉, $Q$에 대해 병렬적으로 연산을 진행함
Q, K, V의 차원은 모델을 구성하는 사람이 Embedding을 어떻게 하냐에 따라 하이퍼파라미터로 결정하는 것!
여기서 Q와 K의 차원은 내적을 해야하니까 같게 설정해야 하고,
V는 가중 평균으로 이용되기 때문에 달라도 되지만 일반적으로는 같게 설정함
Query가 1개일 때 ($q$)의 식
$$
\operatorname{Attention}(q, K, V)=\sum_i \frac{\exp \left(q \cdot k_i\right)}{\sum_j \exp \left(q \cdot k_j\right)} v_i
$$
Query가 여러 개일 때 ($Q$)의 식
$$
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(Q K^T\right) V
$$
여기서 자연스럽게 나오는 특징
- 내적을 해야하니까 Query와 Key는 같은 차원 $d_k$를 가짐
여기서 Query와 Key의 차원이 커질 수록 각 Key의 분산의 합이 전체 분산이 되어 분산이 점점 증가하게 됨
분산(혹은 표준편차)이 커지면 $\operatorname{softmax}$를 거쳤을 때, 큰 값에 확률이 몰리는 현상이 발생함
이를 완화하기 위해서 각 연산에 $\sqrt{d_k}$로 나누어줌 (통계적 증명 생략)
$$
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V
$$
Multi-Head Attention

Attention Module 이미지를 보면 이렇게 겹쳐져 있는 모습으로 되어 있음
1. 동일한 V, K, Q에 대해 병렬적으로 연산 수행
2. 각각의 $W_V, W_K, W_Q$는 서로 독립적으로 다른 값을 가짐
3. 동일한 Sequence에 대해서도 여러 방면에서 봐야되기 때문에 이렇게 하는 것!
$$
\operatorname{MultiHead}(Q, K, V)=\text { Concat }\left(\operatorname{head}_1, \ldots, \text { head }_h\right) W^O
$$
$$
\text { head }_i=\operatorname{Attention}\left(Q W_i^Q, K W_i^K, V W_i^V\right)
$$
아래 예시로 이해해보자

위 이미지처럼 두 단어(Thinking, Machines)로 이루어진 Sequence가 있을 때, Head의 개수를 2개로 하면 다음과 같다.
왼쪽은 0번 째 Head이고 오른쪽은 1번 째 Head로, 각각의 $W$값이 독립적인 것을 확인할 수 있다.
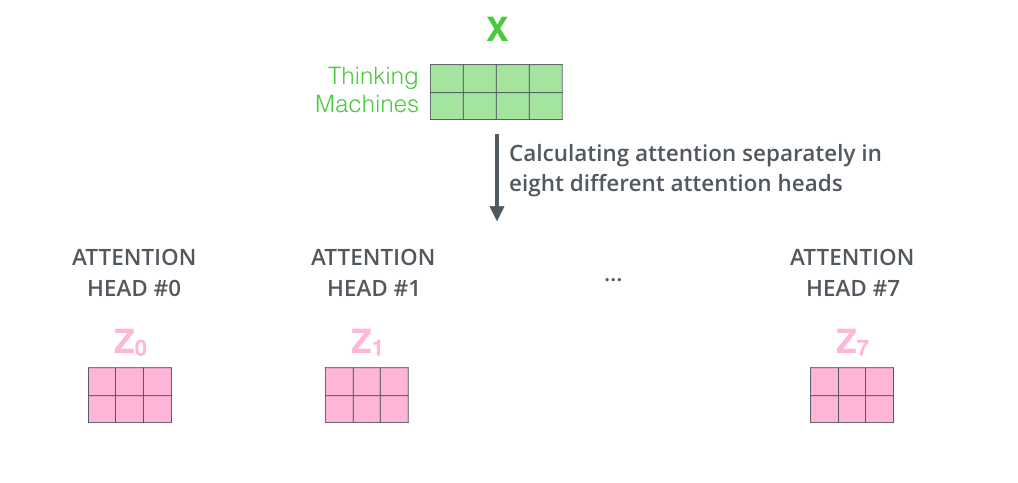
Head의 개수가 8개라고 가정하면, 다음과 같이 총 8개의 Attention 값이 나온다.
이 값들은 모두 여러 방면에서 단어를 관찰한 독립적인 $W$를 가지니까 모두 다른 값이다.

이렇게 나온 8개의 Attention 값들을 가로 방향으로 Concatenate 한다.
Q, K, V 임베딩 벡터의 차원을 3이라고 가정했기 때문에, 열의 길이가 $ 3 \times 8 = 24$가 된다.
해당 길이에 맞춰서 선형 변환 Layer를 구성해준다.
($W_0$의 열의 길이는 원래 단어 임베딩 벡터의 차원인 4에 맞춘 것?)

Recurrent Neural Network와 비교했을 때, 공간 복잡도가 커서 메모리 요구량이 크다.
하지만 Sequential Operations에서 볼 수 있듯이, GPU를 활용한 병렬 연산이 가능해서 Time step 마다 순차적으로 수행하는 RNN보다 훨씬 빠른 연산이 가능하다.
Residual connection
Computer Vision 분야에서 Layer를 깊게 쌓기 위해 활용되는 기법이다.

위 이미지에서 왼쪽으로 삥 돌아서 가리키는 화살표(Add)가 Residual connection이다.
입력값 대비해서 만들고자 하는 벡터의 차잇값을 만들어주는 것으로 활용한다.
<참고>
$ y = F(x) + x $
여기서, $x$는 입력 데이터를 나타내며, $F(x)$는 모델의 층(layer)을 나타냅니다. 따라서, $F(x)$는 입력 데이터 $x$를 변환하여 새로운 출력 데이터 $y$를 생성하는 함수이다.
Residual connection을 적용하면, 입력 데이터 $x$가 $F(x)$의 출력 데이터 $y$에 직접 더해진다. 이렇게 하면, 출력 데이터 $y$는 입력 데이터 $x$에 $F(x)$의 잔차(residual)를 더한 형태로 나타낼 수 있다. 이러한 방식으로 학습을 진행하면, 모델은 입력 데이터 $x$와 $F(x)$의 잔차를 동시에 학습하면서, 입력 데이터의 변화와 출력 데이터의 변화를 더 잘 파악할 수 있게 되어, 모델의 학습 속도를 높이고, Gradient Vanishing 또는 Gradient Exploding 문제를 해결할 수 있다.
참고로 이 그림에서 Output은 Input의 Size와 동일하게 나오게 된다.
Self-Attention Viz
Self-Attention을 시각화해서 이해해보기

위가 Query이고, 아래가 Key와 Value라고 보면 된다.
Self-Attention이기 때문에 Query, Key, Value가 모두 동일한 형태인 것을 볼 수 있다.
Key, Value 부분의 아래 부분에 각각 다른 색상으로 칠해져 있는 것은 grid로, 각각 Head의 Attention Patterns라고 보면 된다.
같은 단어에 대해서도 Multi-Head 구조에서 각각의 Head가 다른 방면으로 Q, K, V를 보기 때문에 다른 색상으로 Interaction을 한다고 이해하자.
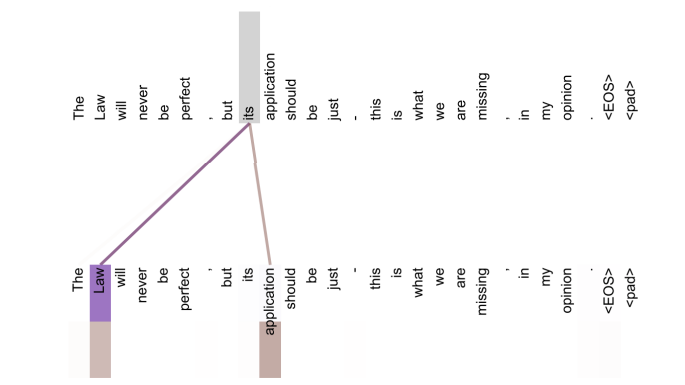
위 이미지는 'its' 라는 Query에 대해 'Law'와 'application'이라는 Key, Value와 상호작용 하는 것을 나타낸 것이다.
보라색으로 칠해진 것이 Head1이고, 갈색 계열이 Head2로 이해하면 된다.
Layer Normalization
위 이미지에서 Norm에 해당하는 것이 Layer Normalization이다.

DL에는 위 이미지처럼 다양한 Normalization 기법이 활용되는데, Transformer에서는 Layer Normalization이 활용된다.
$$
\mu^l=\frac{1}{H} \sum_{i=1}^H a_i^l, \quad \sigma^l=\sqrt{\frac{1}{H} \sum_{i=1}^H\left(a_i^l-\mu^l\right)^2}, \quad h_i=f\left(\frac{g_i}{\sigma_i}\left(a_i-\mu_i\right)+b_i\right)
$$
Batch Normalization은 CV 분야에서 많이 활용되는데 Batch 단위로 나온 값들의 통계량을 계산 후 Normalize를 진행한다.
Transformer 에서는 Layer를 기준으로 Normalization을 진행한다.

이미지처럼 각 단어별(세로)로 표준화를 진행하고, 각 Sequence vector별(가로)로 원하는 평균과 분산을 주입하기 위한 Affine Transformation을 진행한다.
예를 들어, 첫 줄을 보면 표준화된 값인 0.65을 $y = 3x + 1$의 $x$에 넣어서 나온 $y$값이 2.95이다.
맨 위에 있는 이미지처럼 Residual Connection과 Layer Normalization이 결합되어 다음 Layer로 전달된다.
Positional Encoding
위에서 소개한 Transformer의 구조를 살펴보면 RNN과 다르게 각 Word의 Position에 대한 정보가 없다.
예를 들어, [I, love, you] 라는 Sequence와 [you, love, I] 라는 Sequence가 같은 Output을 내게 된다.
이러한 문제를 해결하기 위해서 각 벡터에 위치 정보를 포함시키는 기법이 Positional Encoding 이다.
순서를 특정 지을 수 있는 Unique한 상수 벡터를 입력 벡터에 더해준다.
Transformer에서는 $\sin$ 함수와 $\cos$ 함수를 사용해서 이를 구현한다.
$$
\begin{gathered}
P E_{(p o s, 2 i)}=\sin \left(p o s / 10000^{\left.2 i / d_{m o d e l}\right)}\right. \\
P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{\left.2 i / d_{\text {model }}\right)}\right.
\end{gathered}
$$

위 이미지는 각 차원별로 사용하는 함수 (sin/cos)을 다르게 하고, 주기도 다르게 해서 다른 Position 정보를 부여한다고 이해하면 된다.

위 이미지는 가로로 한 행마다 각각 Position이라고 이해하자.
Postion마다 다른 값을 가지는 것을 확인하면 된다.
Masked Self-Attention
단어를 추론하는 과정에서 뒤에 나오는 단어에 대한 정보를 알고 있으면 Cheating이 발생할 수 있다.
그래서 뒤에 있는 단어들을 가려주는 것이 Masked Self-Attention이다.

Decoder에서의 Q, K, V에 대한 연산을 이미지로 나타낸 것이다.
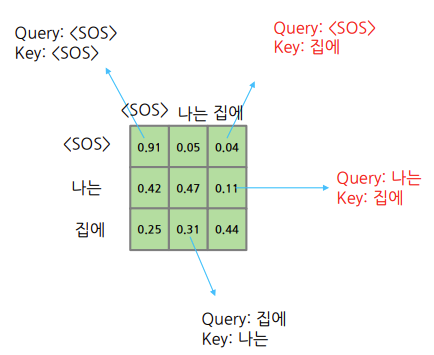
위 이미지처럼 K와 Q의 조합에 따라 $W$값이 나오게 되고, 자기 자신과의 유사도는 높게 나올 수 밖에 없다. (대각 원소)
여기서 상삼각행렬에 해당하는 부분을 Mask한다.

Mask 하는 것을 왼쪽 이미지에서 화살표를 끊는 것처럼 시각화하여 이해할 수 있다.
오른쪽 이미지처럼 윗부분을 0으로 날리고, 남은 값들을 각 행들에 대하여 합이 0인 값으로 Normalize를 진행하면 끝이다.
(코드 보면서 다시 이해해보자, 아직은 헷갈리다..)
High-Level View of Transformer

왼쪽이 Encoder이고 오른쪽이 Decoder이다.
옆에 $ N \times$라고 되어있는 것이 Encoding Block의 수라고 보면 된다.
일반적으로 6, 12, 24, ... 로 설정한다.
Encoder와 Decoder가 연결되는 부분을 보자.
Encoder에서 2개의 화살표가, Decoder에서 하나의 화살표가 Multi-Head Attention으로 들어온다.
Encoder에서 들어오는 것이 Value와 Key 이고, Decoder에서 들어오는 것이 Query이다.
Decoder에서 만들어진 Hidden state vector가 Query로 사용되어, Encoder의 Key와 내적하고 Value로 가중 평균을 구하는 Attention 연산을 진행하는 것이다.
Reference
1. http://jalammar.github.io/illustrated-transformer/
2. http://nlp.seas.harvard.edu/2018/04/03/attention
3. Attention Is All You Need, NeurlIPS'17
'boostcamp AI Tech' 카테고리의 다른 글
| Level2 - DKT (Deep Knowledge Tracing) 프로젝트 회고 (0) | 2023.05.27 |
|---|---|
| Level1 - Book Rating Prediction 프로젝트 회고 (0) | 2023.04.28 |
| boostcamp AI Tech 5기 최종 합격 후기 (2) | 2023.03.15 |