
Model Based Collaborative Filtering
모델 기반 협업 필터링
NBCF와 비교
NBCF 문제
1. Sparsity: 데이터가 부족하면 추천 성능이 떨어지고, 부족하거나 없는 유저는 추천 불가능
2. Scalability: 유저와 아이템이 늘어날수록 연산량도 증가해서 시간이 오래걸림
이런 문제들을 보완하고자 MBCF는 데이터에 숨겨진 유저-아이템 관계의 잠재적 특성/패턴을 이용해서 추천
Parametric Machine Learning 사용
NBCF 대비 MBCF 장점
1. 모델 학습/서빙
- 유저-아이템 데이터는 학습에만 사용되고, 학습된 모델은 압축 형태로 저장
- 이미 학습된 모델을 통해 추천하기 때문에 서빙 속도 빠름
2. Sparsity / Scalability 문제 개선
- NBCF에 비해 Sparse 데이터에서도 좋은 성능을 보임
- 수치적으로 Sparsity Ratiork 99.5%을 넘어도 사용할 수 있음!
- 유저, 아이템 개수가 많이 늘어도 좋은 성능을 보임
3. Overfitting에 좀 더 자유로움
4. Limited Coverage 극복
- NBCF의 경우 공통의 유저, 아이템을 많이 공유해야만 유사도 값이 정확해짐
- NBCF는 해당 유사도 값이 정확하지 않은 경우 이웃의 효과를 보기 어려움
<참고>
Explicit Feedback
→ 직접적인 선호도 (영화 평점, 맛집 별점, ...)
→ 이런 데이터가 많으면 최상이지만 실제 데이터에서는 거의 없음
Implicit Feedback
→ 간접적인 선호도 (클릭 여부, 시청 여부, ...)
→ 상호작용이 있으면 1, 없으면 0을 원소를 갖는 행렬로 표현 가능
→ 현실에서는 Implcit Feedback이 대부분
Latent Factor Model
→ Embedding이란 용어로 많이 사용함
→ 다양하고 복잡한 저와 아이템의 특성을 몇 개의 벡터로 compact하게 표현
→ 저차원으로 행렬 분해 후 각 차원의 의미는 알 수 없음
Singular Value Decomposition
SVD, 특이값 분해
Latent Factor를 구현하는 방법 중 하나

큰 틀에서 보면
유저-아이템 행렬을 $ U $ (유저), $ \Sigma $ (잠재 요인), $ V $ (아이템)로 분해하고,
그 중 의미 있는 잠재 요인($ k $개)만을 선별해서 그 중 유용한 정보만 추려서 행렬을 부분 복원시킴으로서,
가장 중요한 정보로 요약되는 것
순서로 보면 $ R $ → $ U \Sigma V^T $ → $ \hat{U} \hat{\Sigma} \hat{V^T} $ → $ \hat{R} $
Matrix Factorization
- SVD의 한계점을 극복하고자 등장
- 유저-아이템 행렬을 저차원의 유저와 아이템의 Latent Factor 행렬의 곱으로 분해하는 방법
- SVD와 개념적으로 유사하지만, 관측된 선호도만 활해서 관측되지 않은 선호도를 예측하는 일반적인 모델을 만드는 것이 목표
$ R $과 $ \hat{R} $이 최대한 유사하도록 모델을 학습
$$ R \approx P \times Q^T = \hat{R} $$
$ P → |U| \times k $
$ Q → |I| \times k $
Objective Function을 정의하고, 최적화 문제를 푸는 것
true rating: $ r_{u, i} $
predicted rating: $ \hat{r_{u, i}} = p_{u}^{T} q_i $
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} (r_{u, i} - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2) $$
$ r_{u, i} $: 학습 데이터에 있는 유저 $ u $의 아이템 $ i $에 대한 실제 rating
$ p_u, q_i $: 유저(아이템) $ u(i) $의 latent vector (업데이트되는 파라미터)
$ \lambda $가 곱해져 있는 penalty term은 L2-Norm (과적합 방지)
SVD가 행렬 분해를 위해 결측치를 채워넣은 것과 달리, MF에서는 실제 관측된 데이터만을 사용!
MF 학습 방법
1. SGD
Loss: $ L = \sum (r_{u, i} - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2) $
Error: $ e_{ui} = r_{ui} - p_u^T q_i $
Gradient: $ \cfrac{\partial L}{\partial p_u} = \cfrac{ \partial (r_{ui} - p_u^T q_i)^2}{ \partial p_u} + \cfrac{ \partial \lambda ||p_u||_2^2}{ \partial p_u} = -2(r_ui - p_u^Tq_i)q_i + 2 \lambda p_u = -2(e_{ui}q_i - \lambda p_u) $
$ p_u \leftarrow p_u + \eta ( e_{ui} q_i - \lambda p_u) $
$ q_i \leftarrow q_i + \eta ( e_{ui} p_u - \lambda q_i) $
2. ALS
기본 컨셉
- 유저, 아이템 행렬을 번갈아가면서 업데이트
- 두 행렬 중 하나를 상수로 놓고 나머지 행렬 업데이트
- $ p_u, q_i $ 중 하나를 고정하고 다른 하나로 least-square 문제를 푸는 것
SGD 대비 장점
- Sparse한 데이터에 대해 더 Robust함
- 대용량 데이터를 병렬 처리로 빠른 학습 가능
목적 함수는 동일
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} (r_{u, i} - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2) $$
아래 수식으로 $ P, Q $를 번갈아 업데이트
$$ p_u = (Q^T Q + \lambda I )^{-1} Q^T r_u $$
$$ q_i = (P^T P + \lambda I )^{-1} P^T r_i $$
MF 추가적인 테크닉
1. Adding Biases
어떤 유저는 모든 영화에 대해 평점을 짜게 줄 수 있음 (아이템도 마찬가지)
전체 평균, 유저, 아이템의 bias를 추가하여 예측 성능 높이기
기존 목적 함수
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} (r_{u, i} - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2) $$
Bias 추가된 목적 함수
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} (r_{u, i} - \mu - b_u - b_i - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2 + b_u^2 + b_i^2) $$
Error: $ e_{ui} = r_{ui} - \mu - b_u - b_i - p_u^T q_i $
$ b_u \leftarrow b_u + \gamma ( e_{ui} - \lambda b_u) $
$ b_i \leftarrow b_i + \gamma ( e_{ui} - \lambda b_i) $
$ p_u \leftarrow p_u + \gamma ( e_{ui} q_i - \lambda p_u) $
$ q_i \leftarrow q_i + \gamma ( e_{ui} p_u - \lambda q_i) $
2. Adding Confidence Level
모든 평점이 동일한 신뢰도를 갖지 않으므로 $ r_{u, i} $에 대한 신뢰도를 의미하는 $ c_{u, i} $ 추가
예시) 대규모 광고 집행과 같이 특정 아이템이 많이 노출되어 클릭되는 경우
기존 목적 함수 (Bias 추가)
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} (r_{u, i} - \mu - b_u - b_i - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2 + b_u^2 + b_i^2) $$
Confidence Level 추가된 목적 함수
$$ \min\limits_{P, Q} \sum_{observed \; (r_{u, i}} c_{u, i}(r_{u, i} - \mu - b_u - b_i - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2 + b_u^2 + b_i^2) $$
Implicit Feedback을 고려하는 Confidence 예시
$$ c_{ui} = 1 + \alpha \cdot r_{ui} $$
$ \alpha $: Positive Feedback과 Negative Feedback 간의 상대적인 중요도를 조정하는 하이퍼 파라미터
3. Adding Temporal Dynamics
시간이 흐름에 따라 유저, 아이템의 특성은 변화함
이것을 반영하고자 시간에 대한 함수를 추가함
예시) 유저가 시간이 흐르면서 평점을 내리는 기준이 엄격해짐
$$ \hat{r_{ui}(t)} = \mu + b_u (t) + b_i (t) + p_u^T q_i (t) $$
$ \text{Example:} \; b_u(t) = b_u + \alpha_u \cdot sign(t - t_u) \cdot |t - t_u|^{\beta} $
4. Adding Confidence (for Implicit Feedback)
$$ f_{ui} = \begin{cases} 1 & r_{ui} > 0 \\ \hfil 0 & r_{ui} = 0 \end{cases} $$
기존 목적 함수
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} (r_{u, i} - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2) $$
Implicit Feedback을 고려한 목적함수 ($ c $, $ f $ 고려)
$$ \min\limits_{P, Q} \sum_{observed \; r_{u, i}} c_{u, i} (f_{u, i} - p_u^T q_i)^2 + \lambda (||p_u||_2^2 + ||q_i||_2^2) $$
기존 Solution
$$ p_u = (Q^T Q + \lambda I )^{-1} Q^T r_u $$
$$ q_i = (P^T P + \lambda I )^{-1} P^T r_i $$
Confidence, Preference 고려한 Solution
$$ p_u = (Q^T C^u Q + \lambda I )^{-1} Q^T C^u f_u $$
$$ q_i = (P^T C^i P + \lambda I )^{-1} P^T C^i f_i $$
Bayesian Perosnalized Ranking
Bayesian Inference를 기반으로,
Implicit Feedback 데이터를 활용해 MF를 학습할 수 있는 새로운 관점을 제시함
Personalized Ranking
사용자에게 순서(Ranking)가 있는 아이템 리스트를 제공하는 문제
Personalized Ranking을 반영한 최적화
- 유저가 item i보다 j를 더 좋아한다면 이 정보를 활용해 MF의 파라미터를 학습
- 유저 u에 대해 item i > item j 라면, 이것이 유저 u의 Personalized Ranking
사용자의 클릭, 구매 등의 로그는 Implict Feedback 데이터
- 평점에 비해 아이템에 대한 선호도가 분명하지 않음
- Implicit Feedback 추천 시스템은 관측된 데이터만 존재
관측되지 않은 데이터도 고려를 해보자!
- 유저가 아이템에 진짜로 관심이 없는가
- 유저가 실제로 관심이 이지만 아직 모르는 것인가
유저에 아이템에 대한 선호도 랭킹을 생성해서 학습 데이터로 사용!
BPR 접근 절차
1. 가정
- 관측된 아이템이 관측되지 않은 아이템 보다 선호
- 관측된 아이템끼리는 선호도 추론 불가 (선호도 동일)
- 관측되지 않은 아이템끼리도 선호도 추론 불가
관측되지 않은 아이템들에 대해서도 Ranking 가능!
2. 학습 데이터 생성
유저 $ u $가 선호하는 아이템들을 I_u^+ 라고 하면,
$ D_s := \{ (u, i, j) | i \in I_u^+ \wedge j \in I \backslash I_u^+ \} $
$ i $: 관측된 아이템 (선호)
$ j $: 관측되지 않은 아이템 (비선호)

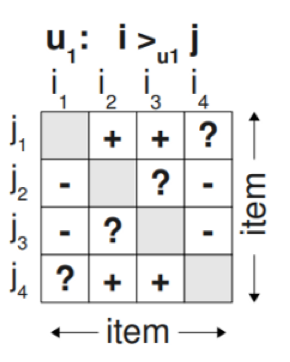
왼쪽 전체 유저-아이템 행렬에서, 오른쪽 유저 $ u_1 $에 대한 행렬로 표현할 수 있다.
위에서 학습 데이터 생성을 마친 거고,
아래부터는 파라미터 학습 방법!
3. 파라미터 학습
최대 사후 확률 추정 (Maximum A Posterior, MAP)
베이즈 정리에 의해,
$$ p( \Theta | >_u ) \propto p( >_u | \Theta ) p ( \Theta ) $$
$ p ( \Theta ) $: 사전확률(prior), 파라미터에 대한 사전 정보
$ p( >_u | \Theta ) $: 가능도(likelihood), 주어진 파라미터에 대한 유저의 선호 정보의 확률
$ p( \Theta | >_u ) $: 사후 확률(posteior), 주어진 유저의 선호 정보에 대한 파라미터의 확률
사후확률을 직접 구하지 못하니까 Bayes 정리를 이용해서 추정하는 것!
Posterior를 최대화한다는 것 → 주어진 유저 선호 정보를 최대한 잘 나타내는 파라미터를 추정하기 한다는 것!
Likelihood: $ p( >_u | \Theta ) $
모든 유저 선호 정보 $ >_u $에 대한 likelihood
$$ \prod_{u \in U} p( >_u | \Theta ) = \prod_{(u, i, j) \in D_s } p ( i >_u j ) = \prod_{(u, i, j) \in D_s} \sigma ( \hat{x}_{uij} ( \Theta ) $$
유저 $ u $의 벡터를 $ p_u $ 아이템 i의 벡터를 $ q_i $ 일 때, 유저 $ u $가 아이템 $ i $를 $ j $보다 좋아할 확률
$ p(i >_u j ) := \sigma ( \hat{x}_{uij} ( \Theta ) ) $, $ \sigma := \cfrac{1}{1 + e^{-x}} \text{(sigmoid function)} $
$ \hat{r}_{ui} = p_u^T q_i $, $ \hat{r}_{uj} = p_u^T q_j $, $ \hat{x}_{uij} = \hat{r}_{ui} - \hat{r}_{uj} = p_u^T q_i - p_u^T q_j $
Prior: $ p( \Theta ) $
파라미터에 대한 사전 확률은 정규분포를 따른다고 가정
정규분포를 행렬로 정의
평균이 모두 0이고, 공분산 행렬이 $ \Sigma_{ \Theta } $인 정규분포
공분산 행렬 $ \Sigma_{ \Theta } $는 $ \lambda_{ \Theta } I $로 설정하여 하이퍼파라미터의 계수 조정
$$ p( \Theta ) \sim N(0, \Sigma_{ \Theta } ) = N (0, \lambda_{ \Theta } I ) $$
BPR 목적 함수
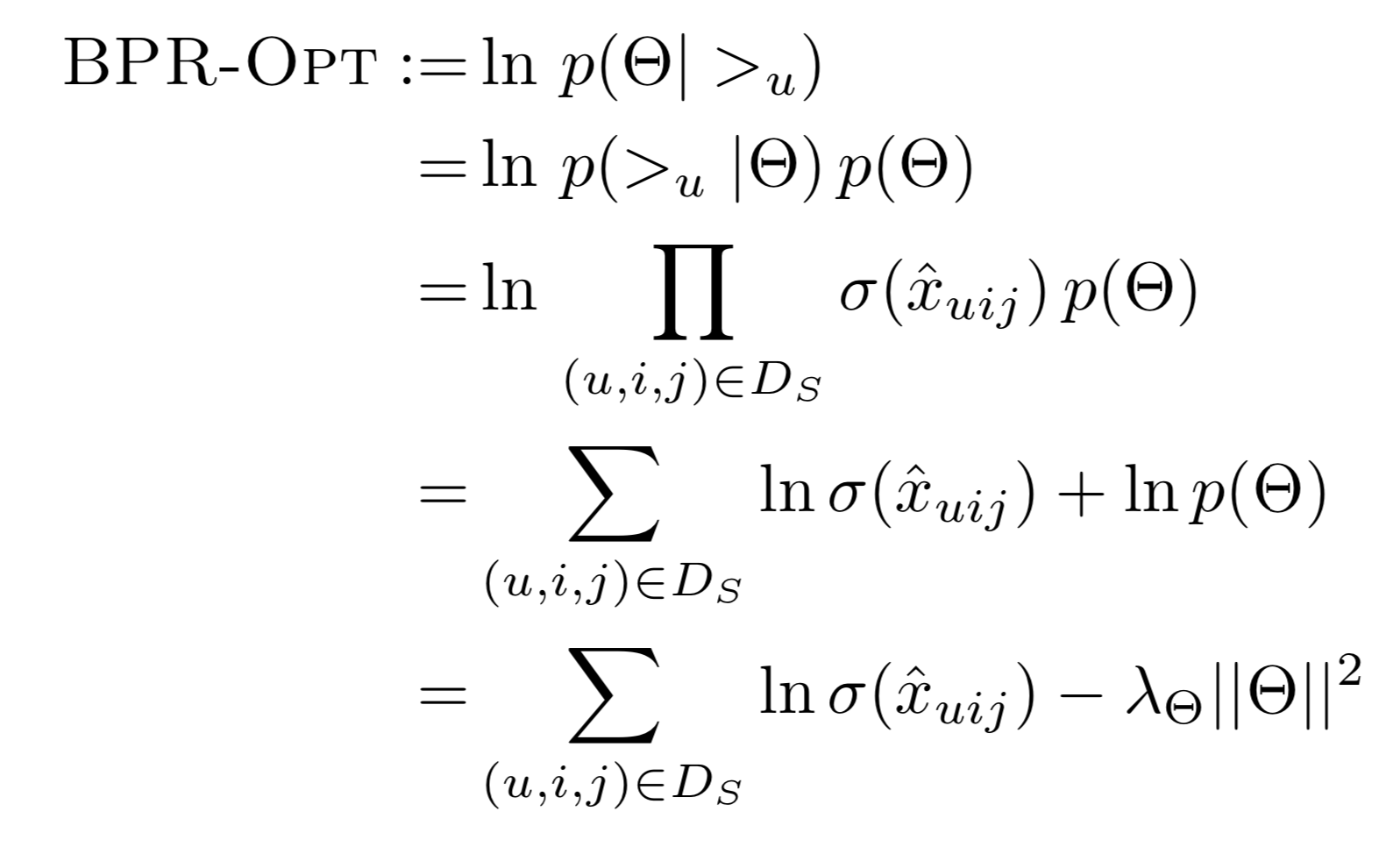
L2 Norm 처럼 규제를 적용함
LEARNBPR
목적 함수가 미분 가능해서 Gradient Descent로 최적화할 수 있음

다만, 일반적인 Gradient Descent는 적절한 학습 방법이 아니여서, Bootstramp 기반의 SGD를 사용
$ D_s := \{ (u, i, j) | i \in I_u^+ \wedge j \in I \backslash I_u^+ \} $

일반적인 SGD 사용
- 보통 $ i $가 $ j $보다 훨씬 많기 때문에 학습의 비대칭 발생
- 동일한 $ u $, $ i $에 대해 계속 업데이트가 되므로 수렴이 잘 안 됨
triples 단위로 랜덤 샘플링
- $ i $와 $ j $의 비대칭 학습 해소
- 동일한 $ u $, $ i $가 계속 등장하지 않기 때문에 성능 우수
MF 모델에 적용하기
유저 $ u $의 벡터를 $ p_u $, 아이템 $ i $의 벡터를 $ q_i $ 라고 하면,
$ \hat{r}_{ui} = p_u^T q_i, \hat{r}_{uj} = p_u^T q_j $
$ \hat{x}_{u, i. j} = \hat{r}_{ui} - \hat{r}_{uj} = p_u^T q_i - p_u6T q_j $
$$ \cfrac{\partial \hat{x}_{u, i, j}}{ \partial \theta } = \begin{cases} q_{ik} - q_{jk} & \text{if} \; \theta = p_{uk} \\ \hfil p_{uk} & \text{if} \; \theta = q_{ik} \\ \hfil -p_{uk} & \text{if} \; \theta = q_{jk} \end{cases} $$
수식 보다 중요한 건,
LEARNBPR로 업데이트 하고자 하는 건,MF의 User-Item Vector (Parameter) 라는 사실!
BPR 절차 요약
1. Implicit Feedback 만을 활용해서 아이템 간의 선호도 도출
2. Maximum A Posterior 방법을 통해 파라미터 최적화
3. LEARNBPR이라는 Bootstrap 기반의 SGD를 활용해 파라미터 업데이트
4. Matrix Factorization에 BPR Optimization을 적용한 결과 성능이 우수함
'boostcamp AI Tech > 추천 시스템' 카테고리의 다른 글
| [RecSys] 추천 시스템에 Deep Learning 활용하기 1 (0) | 2023.04.01 |
|---|---|
| [RecSys] Item2Vec and ANN (0) | 2023.03.31 |
| [RecSys] 추천 시스템 - 협업 필터링 (Collaborative Filtering) - NBCF (0) | 2023.03.27 |
| [RecSys] 추천 시스템 - TF-IDF를 활용한 컨텐츠 기반 추천 (0) | 2023.03.27 |
| [RecSys] 추천 시스템 - 연관 분석 (Association Analysis) (0) | 2023.03.27 |