
Item2Vec은 NLP 분야에서 활용된 Word2Vec에서
Word 대신 Item을 사용해서 추천 시스템에 적용시킨 기법이다.
따라서, Word2Vec 먼저 살펴보고, Item2Vec을 보자
Word2Vec
Embedding
임베딩
주어진 데이터를 낮은 차원의 Vector로 만들어서 표현하는 방법이다.
앞서 학습한 Latent Factor Model과 비슷한 개념이다.
Sparse Representaion: 아이템의 전체 가짓수와 차원 수가 동일
예) One-Hot Encoding, Mult-Hot Encoding
차원의 저주 위험이 있음
Dense Representation: 아이템의 전체 가짓수보다 훨씬 작은 차원으로 표현
예) 면도기 = [0.2, 1.4, -0.2, 0.5], 가위 = [-0.2, 0.5, 1.1, -1.2]
워드 임베딩 (Word Embedding)
텍스트 분석을 위해 Word를 Vector로 표현함
Sparse Representation (one-hot encoding) → Dense representation
임베딩을 하면 단어 간 의미적인 유사도를 구할 수 있음
→ 비슷한 의미를 가진 단어일수록 Embedding Vecot가 가까운 위치에 분포
임베딩으로 표현하기 위해서는 학습 모델이 필요함
- Matrix Factorization도 유저나 아이템의 임베딩으로 볼 수 있으며, 데이터로부터 학습한 Matrix가 곧 임베딩이 됨
Word2Vec 개요
- 뉴럴 네트워크 기반
- 대량 문서 데이터셋을 Vector 공간에 투영
- 압축된 형태의 많은 의미를 갖는 Dense Vector로 표현
- 효율적이고 빠른 학습이 가능
Word2Vec 학습 방법
1. CBOW
Continuous Bag of Words
주변에 있는 단어를 가지고 센터에 있는 단어를 예측
앞뒤로 몇 개($ n $)의 단어를 사용할 것인지 결정
Window의 크기가 $ n $ 이면 실제 예측에 참고할 단어는 앞뒤로 해서 총 $ 2n $개

$ V $: 단어의 총 개수, M: 임베딩 벡터의 사이즈
학습 파라미터: $ W_{V \times M}, W'_{M \times V}

각 주변 단어에 워드 임베딩을 수행한다. (위 예시는 $ n = 1 $)

위와 같이 각 주변 단어에 워드 임베딩을 한 $ x $와 Weight $ W $ 와 곱을 한 값을 $ V $ 로 정의한다.
(위 예시는 $ n = 1 $)

모든 주변 단어의 $ V $값의 산술 평균을 $ v $로 정의한다.

이렇게 정의한 $ v $에 Weight $ W' $를 곱한 값을 $ z $로 정의한다.
$ softmax(z) $를 $ \hat{y} $ (예측값)로 정의하고, 실제 값 one-hot vector $ y $ 와의 차이를 최소화하도록 모델을 학습한다.
2. Skip-Gram
CBOW의 입력층과 출력층이 반대로 구성된 모델
Vector의 평균을 구하는 과정이 없음
일반적을 CBOW보다 Skip-Gram의 성능이 우수하다고 알려져 있음
(Loss를 말하는 게 아니라 단어가 Embedding 되는 Embedding 표현력이 더 좋음)


3. SGNS
Skip-Gram with Negative Sampling
Skip-Gram 기반의 모델로, 주변에 있지 않은 단어를 랜덤 샘플링해서 추가하는 특징이 있음

자연스럽게 Negative Sampling의 개수를 하이퍼파라미터로 갖는데,
Positive Sample 하나당 $ k $개 샘플링
$ k $: 학습 데이터가 적은 경우 $ 5 ~ 20 $개, 충분히 큰 경우 $ 2 ~ 5 $개

중심 단어와 주변 단어가 각각 임베딩 파라미터를 따로 가짐
중심 단어와 주변 단어가 서로 다른 lookup table을 통해 임베딩 됨
위에 있는 사진의 문장과 아래 테이블을 비교해서 보자

1. 중심 단어를 기준으로 주변 단어들과의 내적의 $ sigmoid $를 예측 값으로 하여 0과 1을 분류
2. Backpropagation을 통해 각 임베딩이 업데이트 되면서 모델이 수렴함
3. 최종 생성된 워드 임베딩이 아래 사진처럼 2개이므로, 선택적으로 사용하거나 둘의 평균을 사용
→ 성능 차이가 크지 않아서 선택이 중요하지는 않음

Item2Vec
1. 단어가 아닌 추천 아이템을 Word2Vec을 사용하여 임베딩 (Word → Item)
2. 유저가 소비한 아이템 리스트를 문장으로, 아이템를 단어로 가정하여 Word2Vec 진행
3. SGNS 기반으로 Word2Vec 사용
4. SVD 기반 MF를 사용한 IBCF보다 더 높은 성능과 양질의 추천 결과를 제공!
유저 혹은 세션 별로 소비한 아이템 집합을 생성
→ 시퀀스를 집합으로 바꾸면서 공간적/시간적 정보는 사라짐
→ 대신 집합 안에 존재하는 아이템은 서로 유사하다고 가정
공간적 정보를 무시하니까 동일한 아이템 집합끼리는 모두 Positive Sample (마치 주변 단어처럼)
→ Word2Vec에서는 앞뒤로 $ n $개를 사용했지만, 여기서는 모든 같은 집합의 단어 쌍을 사용
$$ \text{Word2Vec: } \cfrac{1}{K} \sum_{i=1}{K} \sum_{-n \leq j \leq n, j \neq 0} \log p(w_{i+j} | w_i ) $$
$$ \text{Item2Vec: } \cfrac{1}{K} \sum_{i=1}{K} \sum_{j \neq i} \log p(w_j | w_i ) $$
예시) 하나의 동일 세션에서 한 유저가 A, C, B를 소비했다고 가정하면
아이템 집합: {A, B, C}
Word2Vec 데이터: [A, B, 1], [A, C, 1], [B, C, 1], ...
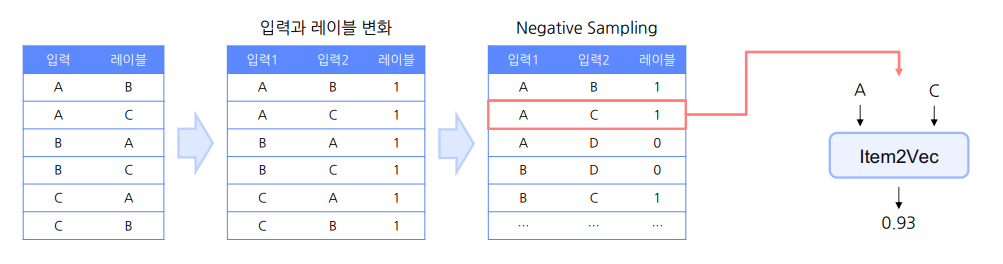
- 사진에 나와있는 D는 랜덤 샘플링으로 들어온 Negative sample인 것을 확인!
- 순서를 고려하지 않는 것도 확인!
Item2Vec Vs. SVD (참고)
두 모델의 아이템 Vector를 t-SNE로 임베딩하여 시각화

Item2Vec의 클러스터링이 더 우수한 것을 확인
* t-SNE(t-distributed stochastic neighbor embedding): 고차원 데이터를 2차원으로 차원 축소하는 기법
ANN
Approximate Nearest Neighbor
ANN 개요
NN은 Neural Network가 아니라, Nearest Neighbor임 (KNN의 그것)
Nearest Neigbor: Vector Space Model에서 내가 원하는 Query Vector와 가장 유사한 Vector를 찾는 알고리즘
MF 모델을 이용해서 추천 아이템을 서빙할 때
- 유저에게 아이템 추천: 해당 유저 Vector와 후보 아이템 Vector들의 유사도 연산이 필요함
- 비슷한 아이템 연관 추천: 해당 Item Vector와 다른 모든 후보 아이템 Vector의 유사도 연산이 필요함
추천 모델 서빙 = Nearet Neighbor Search
→ 모델 학습을 통해 구한 유저/아이템의 Vector가 주어질 때, 주어진 Query Vector의 인접한 이웃을 찾아주는 것
위처럼 유사도 연산을 할 때, 모든 연산을 수행(Brute Force KNN)하려면 엄청난 시간이 걸림
→ 정확도와 연산 시간 사이의 Trade-off가 존재하는데, 그 사이에 적절한 해법을 찾는 것이 ANN의 필요성!
예시) 200ms가 걸려서 100%의 정확도를 구하는 것보다 99%의 정확도로 2-3ms안에 구하는 것이 효과적
ANNOY
spotify에서 개발한 tree-based ANN 기법
주어진 벡터들을 여러 개의 subset으로 나누어 tree 형태의 자료 구조로 구성하고 이를 활용하여 탐색함
<과정>
- Vector Space에서 임의의 두 점을 선택한 뒤, 두 점 사이의 hyperplane로 Vector Sapce를 나눔
- Subspace에 있는 점들의 개수를 node로 하여 binary tree 생성 혹은 갱신
- Subspace 내에 점이 K개 초과로 존재한다면 해당 Subspace에 대해 위 과정 진행
→ ANN을 구하기 위해서는 현재 점을 binary tree에서 검색한 뒤 해당 subspace에서만 NN을 search
hyperplane: 초평면 → n차원을 나누는 n-1 차원의 평면 (2차원상에서는 직선이 초평면)


문제점: 가장 근접한 점이 tree의 다른 node에 있으면 해당 점은 후보 subset에 포함되지 못 함
해결 방안과 관련 파라미터
1. Priority Queue를 사용하여 가까운 다른 node 탐색
→ search_k: NN을 구할 때 탐색하는 node의 개수
2. Binary Tree를 여러 개 생성하여 병렬적으로 탐색
→ number_of_trees: 생성하는 binary tree의 개수
<ANNOY 요약>
1. Search Index를 생성하는 것이 다른 ANN 기법에 비해 간단하고 가벼움
→ 작은 데이터에서 테스트용으로 주로 사용
→ 단, GPU 연산은 지원하지 않음
2. Search 해야 할 이웃의 개수를 알고리즘이 보장함
3. 파라미터 조정을 통해 Accuracy와 Speed의 Trade-Off 조정 가능
4. 단, 기존 생성된 binary tree에 새로운 데이터를 추가할 수 없음
그 외 ANN 기법
1. Hierarchical Navigable Small World Graphs (HNSW)
Navigable: Long-Edge로 탐색
Small World: 전체 Vector에서 물리적으로 가까이 있는 점만 연결
- 벡터를 그래프의 node로 표현하고, 인접한 벡터를 edge로 연결
- Layer를 여러 개 만들어 계층적으로 탐색 진행해서 search 속도 향상
- Layer 0에 모든 노드가 존재, 최상위 Layer로 갈수록 개수가 적어짐 (랜덤 샘플링)
<HNSW 작동 방식>
- 최상위 Layer에서 임의의 노드에서 시작
- 현재 Layer에서 타겟 노드와 가장 가까운노드로 이동
- 현재 Layer에서 더 가까워질 수 없다면 하위 Layer로 이동
- 타겟 노드에 도착할 때까지 2, 3 반복
- 위에서 방문했던 (traverse) 노드들만 후보로 하여 NN을 탐색

위에서부터 아래로 화살표 방향으로 순서를 이해해보자
2. Inverted File Index (IVF)
주어진 Vector를 Clustering을 통해 n 개의 Cluster로 나눠서 저장 (K-means처럼)
Vector의 index를 Cluster별 Inverted list로 저장
- Query Vector에서 해당 Cluster를 찾고, 그 Cluster의 Invert list 안에 있는 Vector들에 대해 탐색
- 탐색해야 하는 Cluster 개수를 증가시킬수록 Accuracy와 Speed의 Trade-Off 발생
Inverted List: 역색인 → 키워드를 통해서 문서를 찾아내는 방식 (색인의 반대)

https://www.pinecone.io/learn/vector-indexes/
3. Product Quantization - Compression
- 기존의 Vector를 n개의 Sub-Vector로 나눔
- 각 Sub-Vector 군에 대해 K-Means Clustering을 통해 centroid를 구함
- 기존의 모든 Vector를 n개의 centroid로 압축해서 표현
두 Vector의 유사도를 구하는 연산이 거의 요구되지 않음
(미리 구한 centroid 사이의 유사도를 활용 → 시간복잡도 $ O(1) $ 수준)
PQ와 IVF를 동시에 사용해서 더 빠르고 효율적인 ANN 수행 가능
→ fiass 라이브러리

https://www.jeremyjordan.me/scaling-nearest-neighbors-search-with-approximate-methods/
위 예시에서 9개의 centroid만 사용하는 것!
'boostcamp AI Tech > 추천 시스템' 카테고리의 다른 글
| [RecSys] 추천 시스템에 Deep Learning 활용하기 2 (0) | 2023.04.03 |
|---|---|
| [RecSys] 추천 시스템에 Deep Learning 활용하기 1 (0) | 2023.04.01 |
| [RecSys] 추천 시스템 - 협업 필터링 (Collaborative Filtering) - MBCF (0) | 2023.03.29 |
| [RecSys] 추천 시스템 - 협업 필터링 (Collaborative Filtering) - NBCF (0) | 2023.03.27 |
| [RecSys] 추천 시스템 - TF-IDF를 활용한 컨텐츠 기반 추천 (0) | 2023.03.27 |