
RecSys with GNN
Graph Neural Network
GNN을 어떻게 추천 시스템에 적용하는지 알아보자
사용하는 이유:
1. 관계나 상호작용 같은 추상적인 개념 다루기에 적합
2. Non-Euclidean Space의 표현 및 학습 가능 (SNS 데이터, ...)
Graph Neural Network: 그래프 데이터에 적용 가능한 신경망
목적: 이웃 노드들 간의 정보를 이용해서 특정 노드를 잘 표현할 수 있는 특징(벡터)을 잘 찾아내는 것
방법: 그래프 및 피쳐 데이터를 인접 행렬로 변환하여 MLP로 사용하는 방법 (Naive Approach) 등이 있음
→ 단, 노드가 많아질수록 연산량이 기하급수적으로 많아지며, 노드의 순서가 바뀌면 의미가 달라질 가능성 존재

왼쪽 그래프처럼 원래 그래프는 순서에 의미를 가지고 있지 않은데,
이를 오른쪽 인접 행렬로 강제로 표현하면 임의로 순서가 들어가버림
이런 한계 때문에 그냥 GNN을 사용하지 않고, Graph Convolution Network(GCN)를 사용함
→보통 GNN 계열 모델을 사용한다고 하면 GCN 기반의 모델이라고 생각하면 됨!
CNN의 특징인 Local Connectivity, Shared Weights, Multi-Layer를 이용하여
Convolution 효과를 만들어서 연산량을 줄이면서 깊은 네트워크로 간접적인 관계까지 특징 추출 가능

출처: "A Comprehensive Survey on Graph Neural Networks" 논문
Neural Graph Collaborative Filtering
유저-아이템 상호작용 (Collaborative Signal)을 GNN으로 임베딩 과정에서 인코딩하는 접근법을 제시한 논문
GCN이 RecSys를 해결하기에 좋은 모델이라는 것을 밝힌 논문!
등장 배경
학습가능한 CF 모델은 유저와 아이템의 임베딩, 상호작용 모델링 두 가지 키포인트가 있음
신경망을 적용한 기존 CF 모델들은 유저-아이템의 상호작용을 임베딩 단계에서 접근하지 못함
→ 임베딩이 일어난 이후에 임베딩을 Concatenate하기 때문!
→ 임베딩과 상호작용이 분리되어 있음
→ Latent Factor 추출을 Interaction Function에만 의존하므로 Sub-Optimal한 임베딩을 사용
→ 부정확한 추천이 발생할 수 있음
기본 아이디어
Collaborative Signal
유저-아이템의 상호작용이 임베딩 단에서부터 학습할 수 있도록 하자!
유저, 아이템 개수가 많아질수록 모든 상호작용을 표현하기엔 한계가 존재함
GNN을 통해 High-order Connectivity를 임베딩 (경로가 1보다 큰 연결)

출처: "Neural Graph Collaborative Filtering" 논문
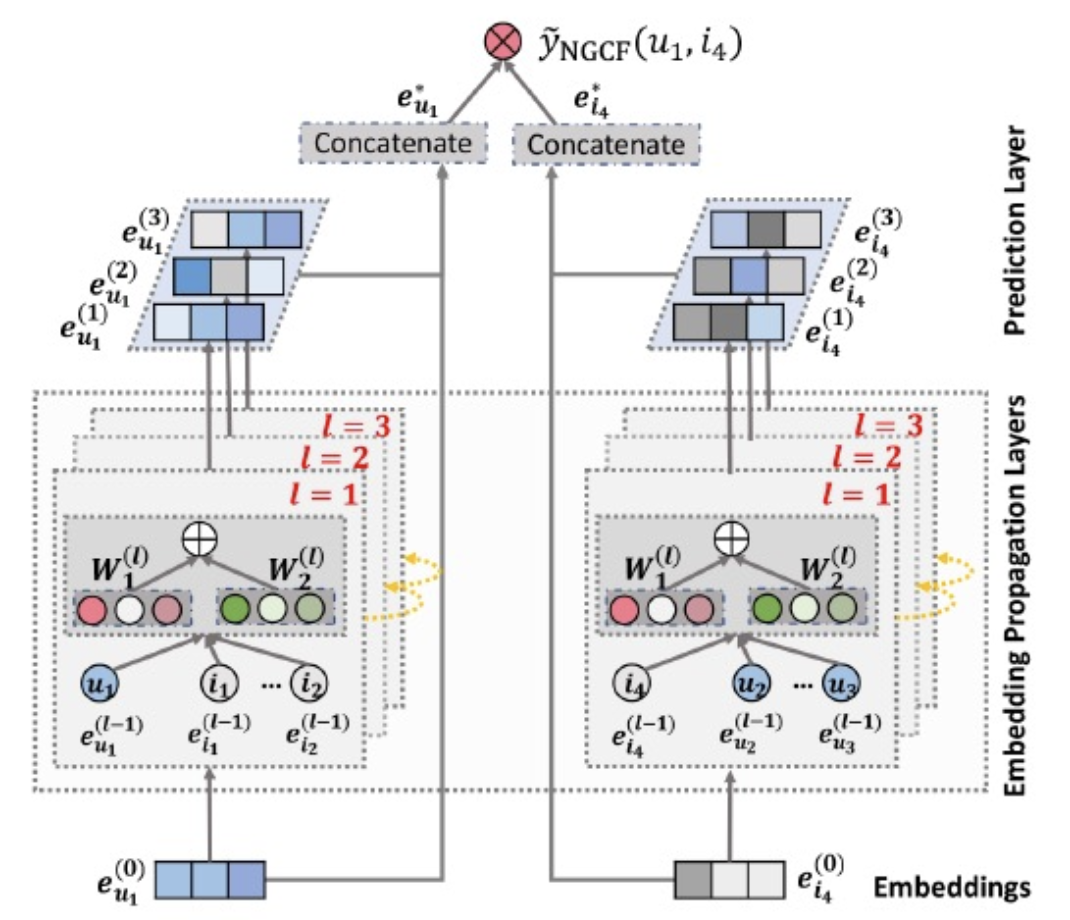
전체 구조
1. 임베딩 레이어 (Embedding Layer)
→ 유저-아이템의 초기 임베딩 제공
→ One-Hot Encoding
2. 임베딩 전파 레이어 (Embedding Propagation Layer)
→ High-order connectivity 학습
3. 유저-아이템 선호도 예측 레이어 (Prediction Layer)
→ 서로 다른 전파 레이어에서 정제된 임베딩을 Concatenate

출처: "Neural Graph Collaborative Filtering" 논문
왼쪽은 유저 노드 기준으로 전파되는 임베딩이 전파되는 유저 임베딩 레이어
오른쪽은 아이템 노드 기준으로 전파되는 임베딩이 전파되는 아이템 임베딩 레이어
1. 임베딩 레이어
→ 임베딩을 생성한다
$$ E = [ e_{u_1}, \ldots , e_{u_N} , \; e_{i_1}, \ldots, e_{i_M} ] $$
$ e_u $: 유저 $ u $에 대한 임베딩, $ e_i $: 아이템 $ i $에 대한 임베딩
기존의 MF, Neural CF 모델에서는 임베딩이 곧바로 interaction function에 입력됨
NGCF에서는 이 임베딩을 GNN 상에서 전파시켜서 정제함 (refine)
→ Collaborative Signal을 명시적으로 임베딩 레이어에 주입하는 과정
2. 임베딩 전파 레이어
유저-아이템의 collaborative signal을 담은 'message'를 구성하고 결합하는 단계
(유저 노드 기준)
Message Construction: 유저-아이템 간 affinity를 고려할 수 있도록 메시지 구성 (weight sharing)
$$ m_{u \leftarrow i} = \cfrac{1}{\sqrt{|N_u| |N_i|}} (W_1 e_i + W_2 (e_i \odot e_u) ) $$
분모 term에 들어간 것은 너무 커지는 것을 방지하기 위한 Normalization
Message Aggregation: $ u $의 이웃 노드로부터 전파된 message들을 결합하면 1-hop 전파를 통한 임베딩 완료
$$ e_u^{(1)} = \text{LeakyReLU} (m_{u \leftarrow u + \sum_{i \in N_u} m_{u \leftarrow i} ) $$
$ W_1, W_2 $: weight matrix
$ \odot $: element-wise production
$ N_u, N_i $: 유저, 아이템의 이웃한 유저, 아이템 집함
$ l $개의 임베딩 전파 레이어를 쌓으면, 유저 노드는 $ l $-차 이웃으로부터 전파된 메시지 이용 가능
$ l $단계에서 유저 $ u $의 임베딩 ( $ l - 1 $ ) 단계의 임베딩을 통해 재귀적으로 형성 (Higher order propagation)
점화식 표현
$$ e_u^{l} = \text{LeakyReLU} (m_{u \leftarrow u}^{(l)} + \sum_{i \in N_u} m_{u \leftarrow i}^{(l)} ) $$
$$ m_{u \leftarrow i}^{(l)} = p_{ui} (W_1^{(l)} e_i^{(l-1)} + W_2^{(l-1)} ( e_i^{(l-1)} \odot e_u^{(l-1)} ) )$$
$$ m_{u \leftarrow u}^{(l)} = W_1^{(l)} e_u^{(l-1)} $$
3. 유저-아이템 선호도 예측 레이어
$ L $차 까지의 임베딩 벡터를 concatenate하여 최종 임베딩 벡터를 계산한 후,
유저-아이템 벡터를 내적하여 최종 선호도 예측값 계산
$$ e_u^* = e_u^{(0)} || \ldots || e_u^{(L)}, \; \; e_i^* = e_i^{(0)} || \ldots ||e_i^{(L)} $$
$ || $: concatenate 연산자
$$ \hat{y}_{NGCF}(u, i) = {e_u^*}^T e_i^* $$
최종적으로 임베딩 전파 레이어가 많아질수록 모델의 추천 성능 향상을 보임
→ 하지만 레이어가 너무 많으면 ovefitting 발생 가능
→ 실험 결과, $ L $이 3 ~ 4일 때 가장 좋은 성능을 보임
→ 일반 MF 보다 더 빠르게 수렴하고 Recall도 더 높음
→ 일반 MF 보다 유저-아이템이 임베딩 공간에서 더 명확하게 구분 (레어어가 많아지면 더 명확해짐)
LightGCN
사진 출처는 "LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation" 논문
GCN의 가장 핵심적인 부분만 사용하여, 더 정확하고 가벼운 추천 모델
핵심 아이디어
1. Light Graph Convolution
→ 이웃 노드의 임베딩을 가중합 하는 것이 covolution의 전부, 학습 파라미터와 연산량 감소
2. Layer Combination
→ 레이어가 깊어질수록 강도가 야해질 것이라는 아이디어를 적용해서 모델 단순화

왼쪽은 기존 NGCF 모델 구조, 오른쪽은 LightGCN 모델 구조
Layer Combination (Weighted sum)과 Light Graph Convolution을 적용해서 더 가벼운 모델 구성
- Feature Transform, Nonlinear Activation을 제거하고, 대신 가중합으로 GCN 적용
- 연결 노드만 사용해서 self-connection 없음
- 학습 파라미터는 0번째 임베딩 레이어에서만 존재
기존 NGCF 임베딩 벡터
$$ e_u^{(k+1)} = \sigma ( W_1 e_u^{(k)} + \sum_{i \in N_u} \cfrac{1}{\sqrt{|N_u||N_i|}} (W_1 e_i^{(k)} \odot e_u^{(k)} )) ) $$
$$ e_i^{(k+1)} = \sigma ( W_1 e_i^{(k)} + \sum_{i \in N_i} \cfrac{1}{\sqrt{|N_u||N_i|}} (W_1 e_u^{(k)} \odot e_i^{(k)} )) ) $$
LignGCN 임베딩 벡터
$$ e_u^{(k+1)} = \sigma_{i \in N_u} \cfrac{1}{\sqrt{|N_u|} \sqrt{|N_i|}} e_i^{(k)} $$
$$ e_i^{(k+1)} = \sigma_{i \in N_i} \cfrac{1}{\sqrt{|N_i|} \sqrt{|N_u|}} e_u^{(k)} $$
최종 예측을 위해 각 레이어의 임베딩을 결합하는 방법도 다름
NGCF는 아래처럼 concatenate 했음
$$ e_u^* = e_u^{(0)} || \ldots || e_u^{(L)}, \; \; e_i^* = e_i^{(0)} || \ldots || e_i^{(L)} $$
LightGCN은 $ k $-층으로 된 레이어의 임베딩을 각각 $ \alpha_k $배 하여 가중합으로 계산 (가중합으로 정보 압축)
$ \alpha_k $는 $ k $-층 임베딩 벡터의 가중치로, 하이퍼 파라미터나 학습 파라미터 둘 다 가능
- 성능 차이는 거의 없어서 뭘로 사용하든 상관 없음
- 논문에서는 $ (K + 1 ) ^{-1} $ 사용 → K가 깊어질수록 가중치 감소
$$ e_u = \sum_{k=0}^K \alpha_k e_u^{(k)} ; \; \; e_i = \sum_{k=0}^K \alpha_k e_i^{(k)} $$
RecSys with RNN
RNN
순환 신경망 (Recurrent Neural Network)를 어떻게 추천 시스템에 적용하는지 알아보자
사진 출처는 http://colah.github.io/posts/2015-08-Understanding-LSTMs/
(Vanilla) RNN
- 시퀀스 데이터의 처리와 이해에 좋은 성능을 보이는 신경망 구조로 제안됨
- 현재의 state가 그 다음 state에 영향을 미치도록 루프 구조 고안

Long-Short Term Memory (LSTM)
- 시퀀스가 길어지는 경우 학습 능력이 현저하게 저하되는 RNN의 한계 극복
- 장기 의존성 해결을 위해 Cell State라는 구조를 고안
- forget gate, input gate, cell state update로 구성

Gated Recurrent Unit (GRU)
- LSTM의 변형으로, 출력 게이트가 따로 없어 파라미터와 연산량이 적은 모델
- reset gate, update gate로 구성
- LSTM과 명확한 성능 차이가 없으면서 훨씬 가벼움 (각 task에 따라 모델 선택)

GRU4Rec
위에서 소개한 GRU를 RecSys에 적용한 모델
사진 출처는 "Session-Based Recommendation with Recurrent Neural Networks" 논문
Session based RecSys
→ 고객이 선호는 시간이 흐름에 따라 바뀜
→ 지금 고객이 좋아하는 게 무엇인가?
Session: 유저가 서비스를 하는 동안의 행동을 기록한 데이터

Session이라는 시퀀스를 GRU 레이어에 입력하여 바로 다음에 올 확률이 가장 높은 아이템을 추천
입력: One-Hot Encoding된 Session
(→ 임베딩 레이어를 사용하지 않았을 때의 성능이 더 높음)
(→ 이 모델 이후 RNN 계열 추천 모델에서 임베딩을 사용한 모델도 많음, 따라서 중요한 내용은 아님)
GRU 레이어: 시퀀스 상 모든 아이템들에 대한 맥락적 관계 학습
출력: 다음에 골라질 아이템에 대한 선호도 스코어

학습
1. Session Parallel Mini batches
→ 대부분의 세션은 매우 짧지만, 길이가 긴 것도 존재함
→ 길이가 짧은 세션들이 모두 사용되어 idel 하지 않도록, 세션을 병렬적으로 구성하여 Mini batches 학습
2. Sampling on the output
→ 현실에서는 아이템 수가 매우 많기 때문에 모든 후보 아이템의 확률 계산 어려움
→ 따라서, 아이템을 negative sampling 후 subset만으로 loss 계산하기
→ 사용자가 상호작용 하지 않은 아이템은 존재 자체를 몰랐거나 관심이 없는 것
→ 아이템의 인기가 높은데도 상호작용이 없는 것을 사용자가 관심이 없는 아이템이라고 가정
→ 따라서, Negative Sampling을 할 때, 인기가 높은 것 위주로 진행
'boostcamp AI Tech > 추천 시스템' 카테고리의 다른 글
| [RecSys] Context-aware Recommendation (0) | 2023.04.07 |
|---|---|
| [RecSys] 추천 시스템에 Deep Learning 활용하기 1 (0) | 2023.04.01 |
| [RecSys] Item2Vec and ANN (0) | 2023.03.31 |
| [RecSys] 추천 시스템 - 협업 필터링 (Collaborative Filtering) - MBCF (0) | 2023.03.29 |
| [RecSys] 추천 시스템 - 협업 필터링 (Collaborative Filtering) - NBCF (0) | 2023.03.27 |